learning world model learning
The Status Quo
GPT-2 from OpenAI was trained on 40GB or 10 billion tokens of data. This was the accumulation of over 8 million web pages from the internet. Let's assume for the same amount of data, we can train a comparable model for general robotics, here's how much it would cost us:
- Total amount of tokens: 10 billion.
- Tokens per hour of data collection (assumption based on current tokenization methods): 500,000 tokens/hour.
- Total hours: 10,000,000,000 / 500,000 = 20,000 hours = 2,500 days (assuming 8 hours/day) ~= 10 years (with 260 working days/year)
- Cost per hour (minimum wage in US): $7.25/hour + Misc Cost = $20/hour
- Total cost: ~$400,000 ~= 0.5 million dollars
We used several generous assumptions here, especially for the equivalence of tokens between text and modalities such as video and most importantly a similar scaling law between robotics and LLM. It's also notable that most LLM models nowadays are trained on much larger datasets such as FineWeb (~15 trillion Tokens) and of much higher diversity.
To scale real world data collection to such point would require enormous efforts and capital in the range of billions. Collecting diverse data in the real world is not simply deploying your robot everywhere. It also requires building the infrastructure necessary for such task: network infrastructure, equipment infrastructure.
There are multiple methods teams are exploring to close this data gap: from realistic simulation to low-cost data collection with UMI to world models.
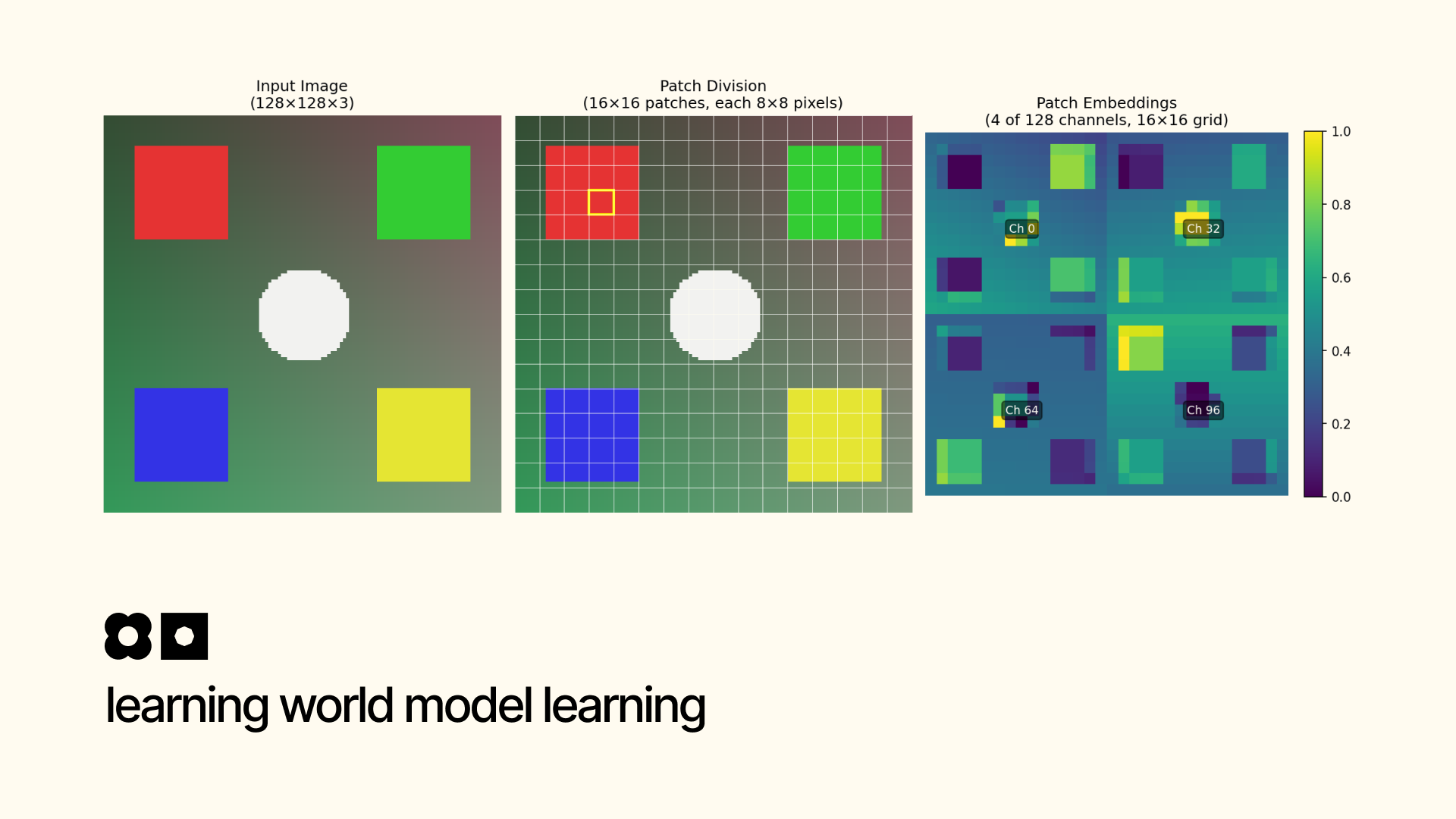
In this series of articles, I'll go through why I believe in world models and how to build one from scratch in first principles.
How To Read This Series
Due to the limitation of my blog, this series is hosted inside a GitHub Repository. I want to provide an agentic learning experience where you can chat with an agent about the content of the blog and test modules on the fly. Currently, this means cloning the repository to your local machine and using a coding agent on it. A CLAUDE.md is provided out of the box to replicate my way of reasoning and thinking, keeping the essence of the series.
Regardless, you can read the whole series online from GitHub. It is divided into 4 major articles:
- Introduction covers the intuition and architecture of a simple world model. Read it here.
- Video Tokenizer covers how world models tokenize videos for downstream processing. Read it here.
- Inverse Dynamics covers how world models can learn from raw videos without action annotations. Read it here.
- Dynamics covers how world models learn to predict the future from current actions and states. Read it here.
In the future, I will develop more articles in this topic as well. They will all be located in this repository. New articles will range from research questions, paper discussions to practicalities in serving world models in the wild.
How To Contribute
Due to the nature of this series being a repository, I warmly welcome all contributions. This ranges from fact checks to new visualizations to new features. To encourage this even more, I include a to-do inside each article I write as an exercise for readers and potential addition to the series.
For private conversations, my email is binhpham@binhph.am and my X is @pham_blnh. For public conversations, you are welcomed to open a pull request or issue within the repository.
P/S: A Rant
imo, world model is the key to solving the data gap in robotics.only at the beginning of this year and end of last year did we see large datasets that hover around the 10k hours mark like 10Kh RealOmin, which was recorded with an UMI.this is much paler in comparison to the data scale that LLM has been trained on.why not more? well, building the infrastructure to scale data collection is not easy. we need new pipeline, new portable hardware like UMI and extensible ones as well since the landscape is changing everyday.all large scale (>5k hours) dataset and collection pipeline don’t contain tactile information yet, which is crucial for dexterous manipulation and safety.imagine building the infra now without support for other modalities such as tactile only to add it later.so the biggest moat for any robotics company is the data collection moat .i.e. how to collect quality data and adapt to new modalities faster than any other companies.this is a moat that is simply too powerful to have.the most recent 1X’s world model is trained on 900 hours of egocentric videos, 400 hours of unfiltered robot data, and only 70 hours of quality task-specific data.it shows the promise of training robots on internet scale data through a hierarchy of quality data. only in the final training step do they need a small amount of task and embodiment specifc data.nvidia sonic mentions this hierarchy very well.